
There are many benchmarks comparing AI models. I don't doubt they are trustworthy, but I wanted to double-check which model best fits my use case instead of choosing one blindly based on benchmarks.
When I started building SnapJournal, one of the first big decisions was which AI vision model to use. SnapJournal takes photos of handwritten planners and journals and turns them into digital calendar events so the AI needs to read messy handwriting, understand the spatial layout of a page, and extract structured data like event titles, dates, and times.
Generic benchmarks measure things like reasoning ability, code generation and others. But none of them tell me: "Can this model read my chicken-scratch planner and pull out the right schedule?" So I decided to run my own tests.

If you want to explore an interactive dashboard of the results, check out SnapJournal's website.
Process
- The setup
- The criteria
- F1 score
- Consistency
- Accuracy, speed, cost
- The winner
- Top performer
- Bonus - GPT 5.4-Pro
- Which one would you choose?
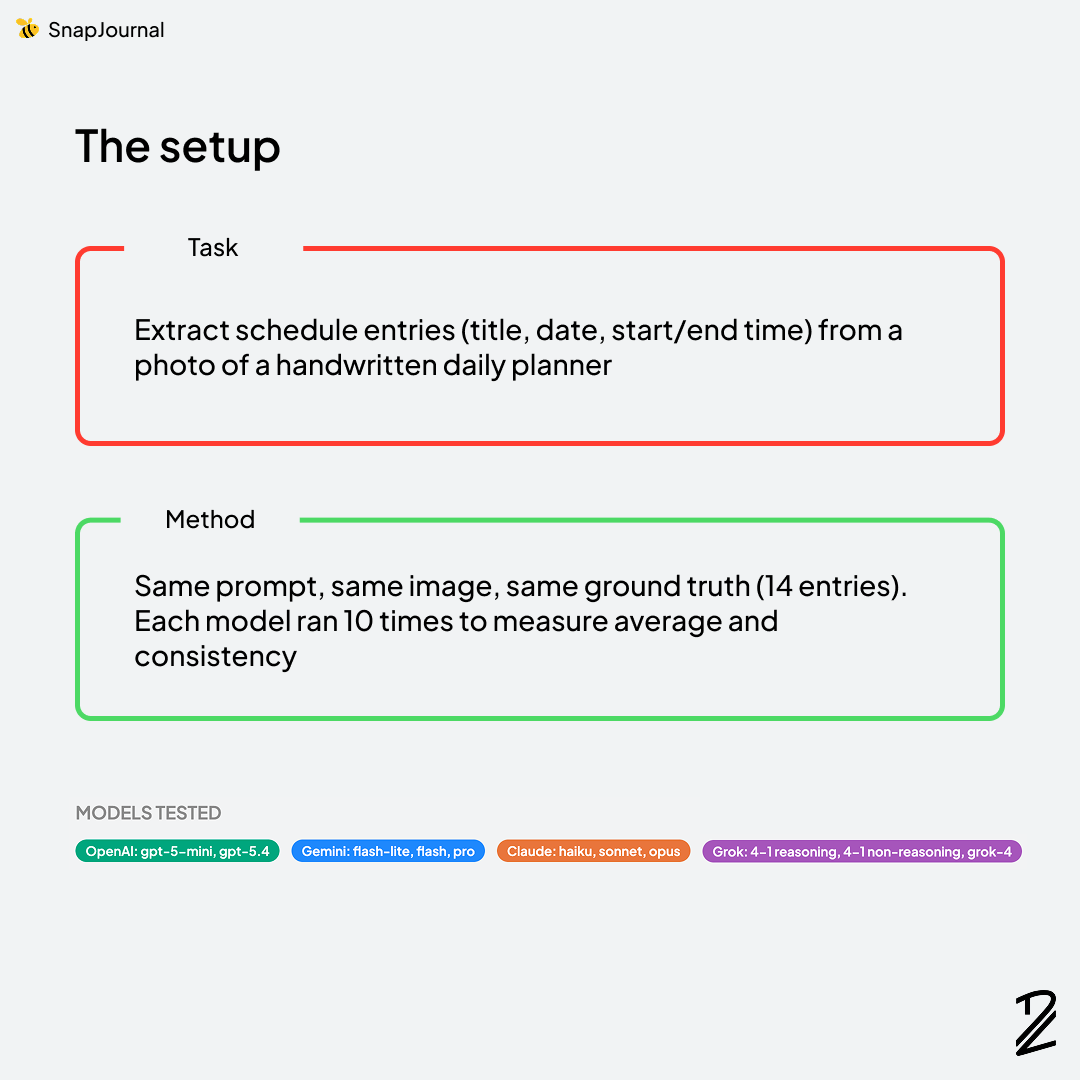
The setup
I took a handwritten planner photo and ran them through four AI vision models: Claude (Anthropic), GPT (OpenAI), Gemini (Google), and Grok (xAI). Each model received the exact same prompt, asking it to extract schedule entries — event title, date, time, and duration — from the images. I ran each test multiple times to make sure the results weren't just a lucky (or unlucky) one-off.

The criteria
I needed criteria that actually matter for my use case, not just what looks good on a leaderboard. Here's what I evaluated:
- F1 Score — Does the model catch every entry on the page without hallucinating events that aren't there?
- Consistency — If a user snaps the same planner page twice, do they get the same results?
- Latency — How long does the user have to wait after taking a photo?
- Cost — Can I afford to run this at scale without burning through my budget?
Let's break each one down.

F1 score
F1 score balances two things: precision (did the model avoid making stuff up?) and recall (did it catch everything on the page?). A high F1 score means the model is both accurate and thorough which is exactly what I need. If the model misses an event, the user has to manually add it. If it hallucates an event that doesn't exist, the user has to delete it. Both are bad experiences.
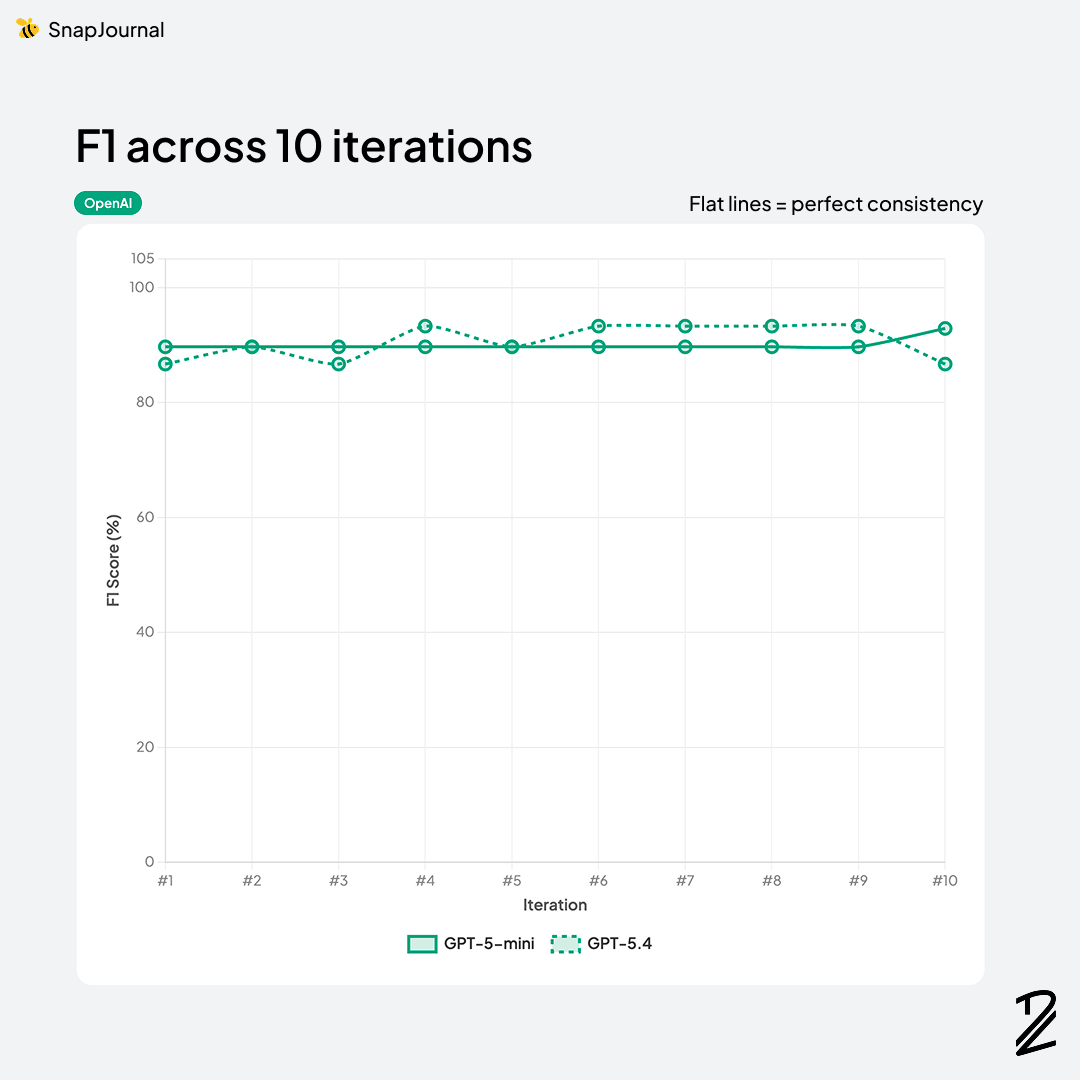
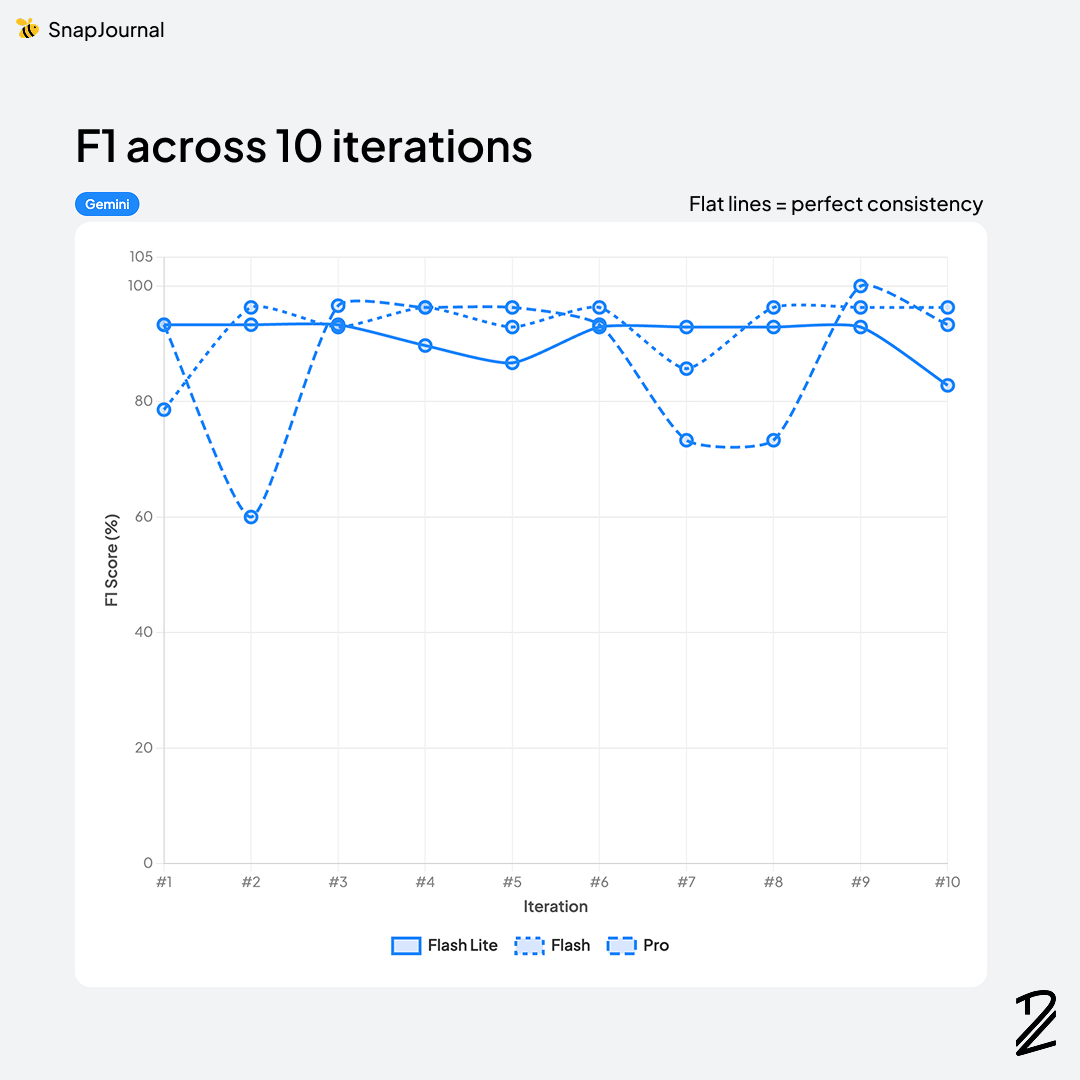
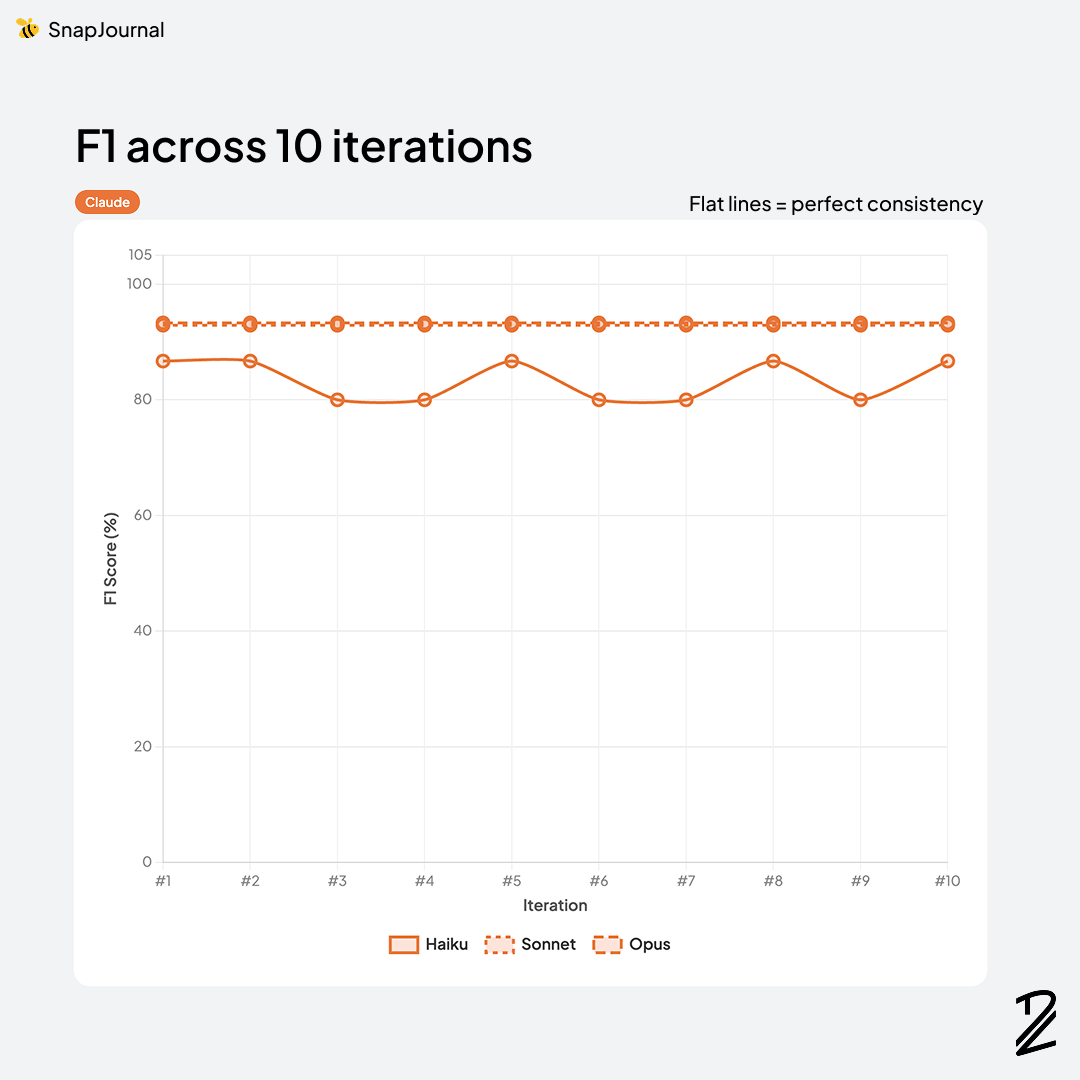

Claude dominated this category. Opus-4-6 took the top spot at 93.3% and Sonnet-4-6 was right behind at 92.9%. Both models consistently identified the correct events, nailed the dates and times, and rarely hallucinated entries that weren't on the page.
Gemini performed surprisingly well — Gemini-3-flash scored 92.8%, nearly tied with Claude Sonnet, and Gemini-3.1-flash-lite came in at 91.1%. The lighter models punched above their weight here.
OpenAI was solid but a step behind — GPT-5.4 at 90.6% and GPT-5-mini at 90.0%. Accurate enough to be usable, but the gap from Claude was consistent across runs. Interestingly, Gemini 3.1-pro (87.6%) fell below both OpenAI models despite being a "pro" tier model.
Claude Haiku-4-5 at 83.3% showed a noticeable drop from its bigger siblings — a reminder that model size still matters for vision tasks like handwriting recognition.
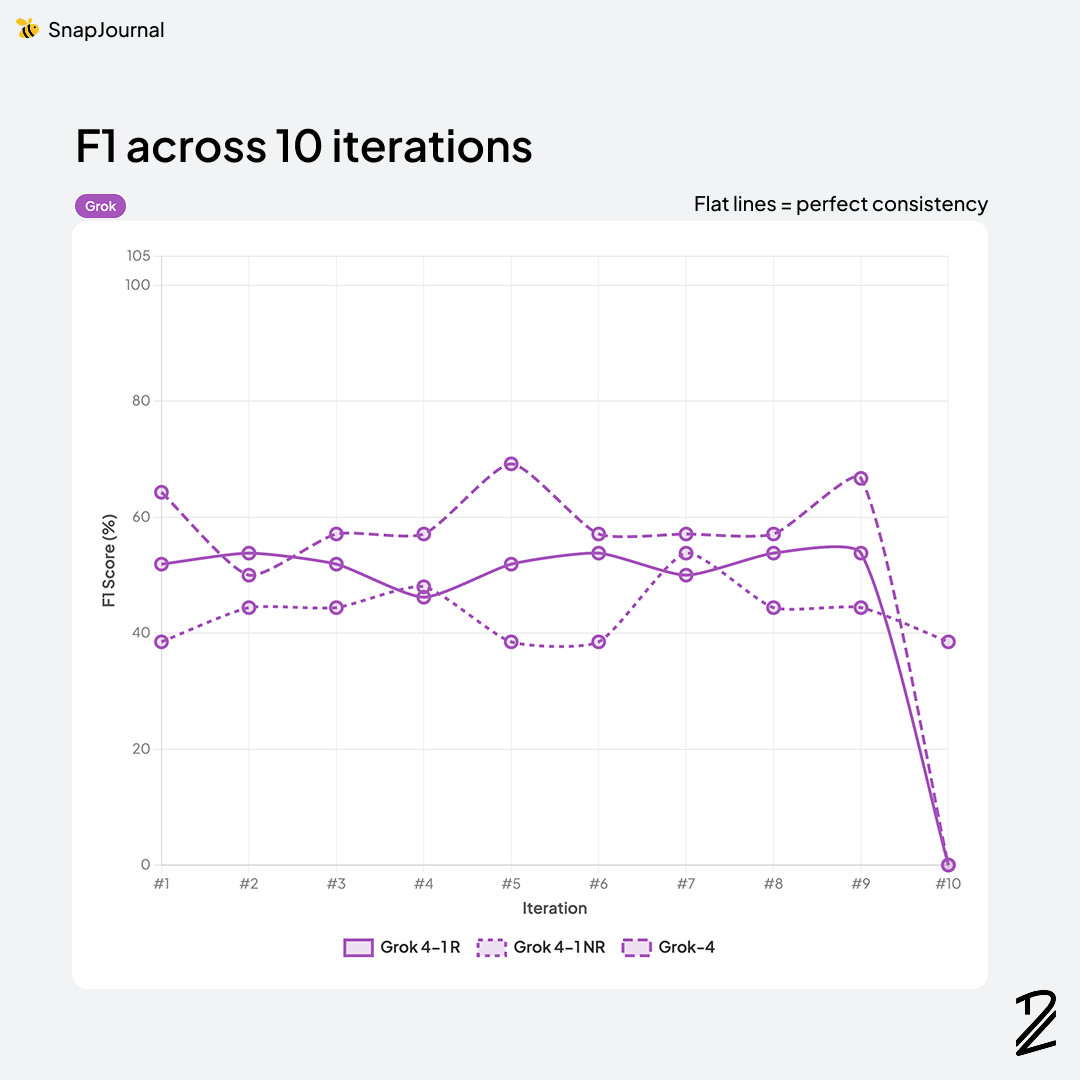
Grok was a different story entirely. Grok-4 scored 53.6%, and other models (Grok-4-1 reasoning at 46.7%, Grok-4-1 non-reasoning at 43.3%) were essentially unusable for this task. They missed entries, confused spatial layouts, and hallucinated events that didn't exist. Not even close to production-ready for SnapJournal's use case. After I checked the raw responses, I found that Grok models are not good for recognizing handwritings.
Latency
Speed matters more than most people think. When a user takes a photo and hits submit, they're watching a loading screen. Every second feels like ten. I measured the response time for each model processing the same images because even the most accurate model in the world is useless if users give up waiting.
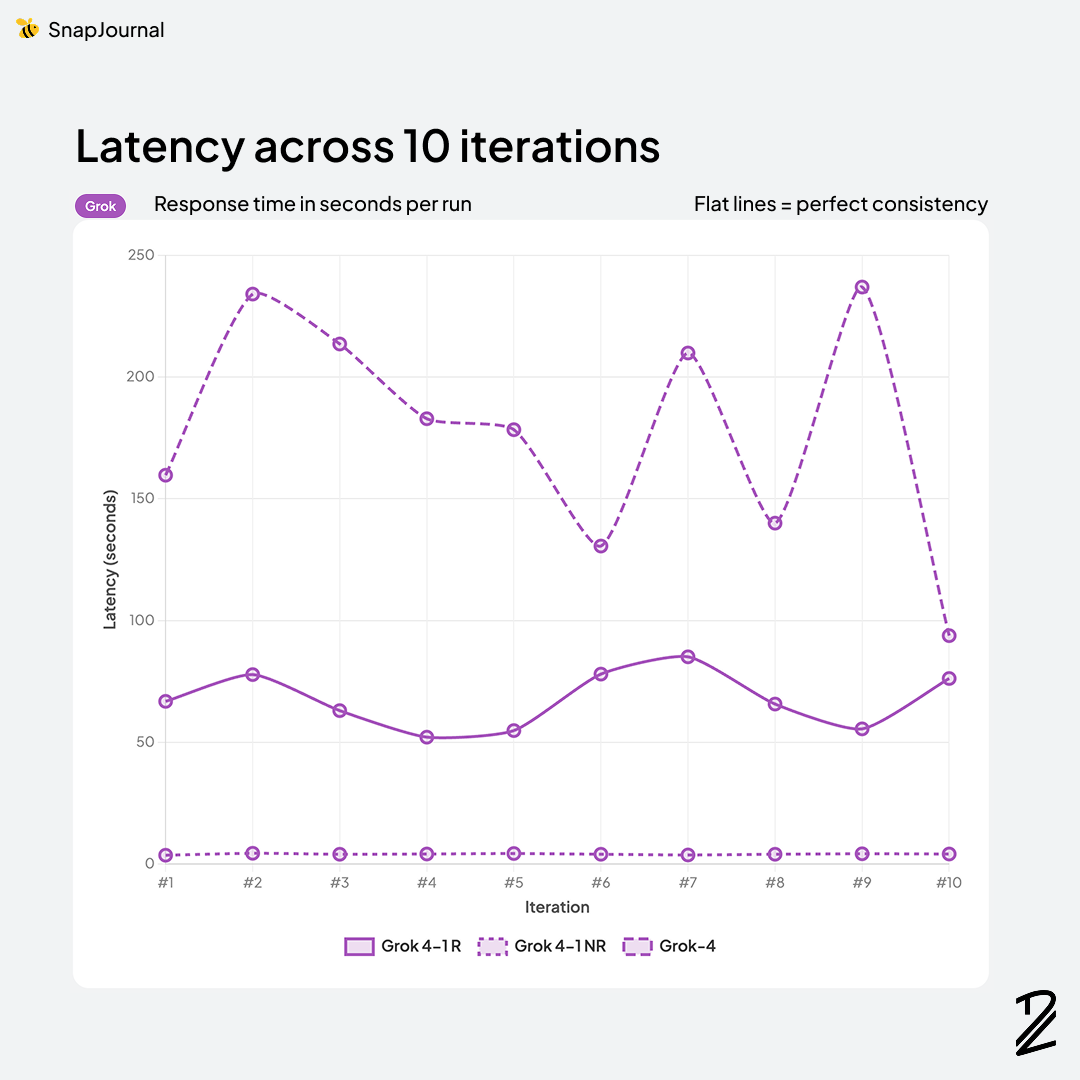
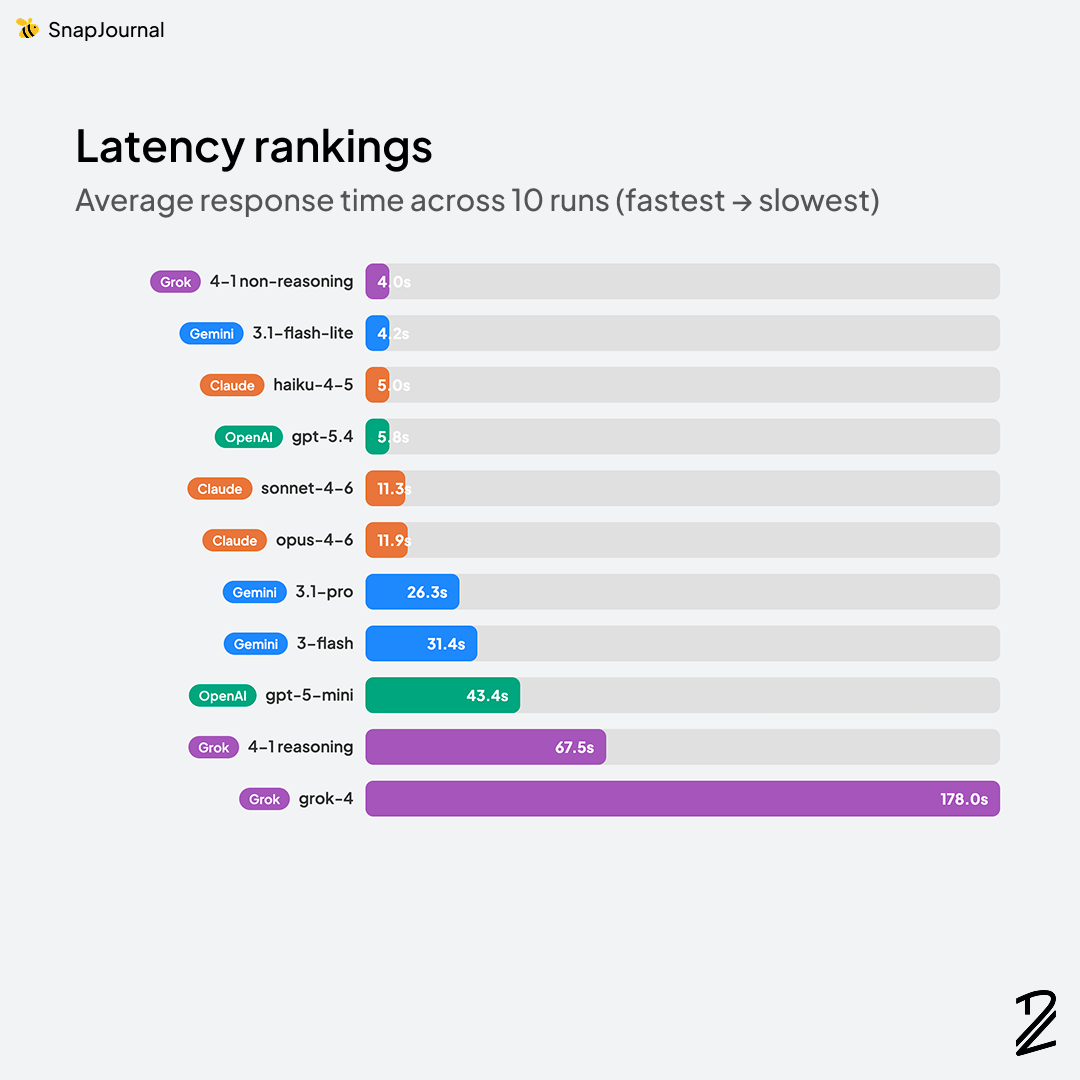
The speed rankings told a completely different story from accuracy.
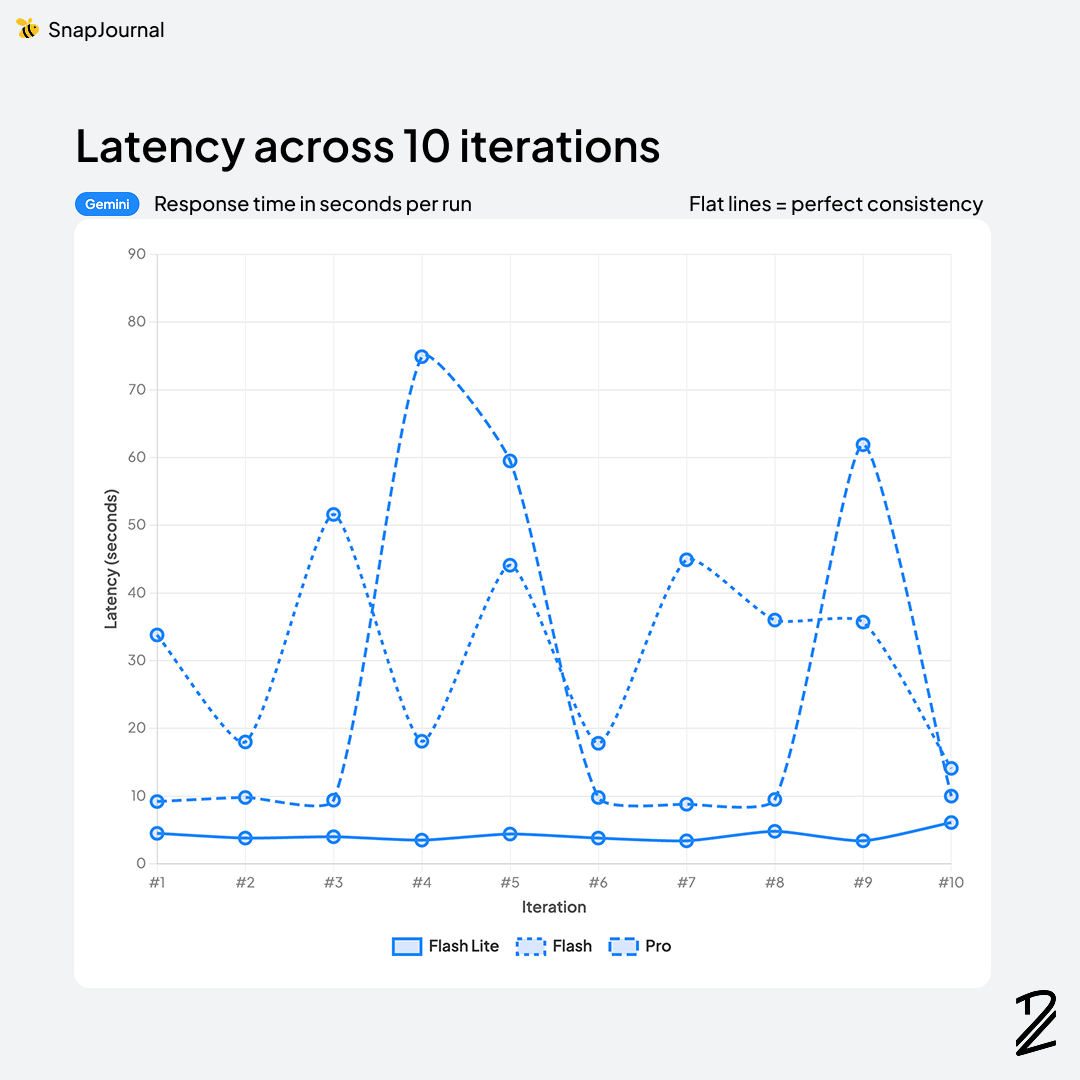
Grok 4-1-non-reasoning was actually the fastest at 4.0s, followed closely by Gemini 3.1-flash-lite at 4.2s. But remember Grok's F1 score was 43.3%. Being fast doesn't help if the results are wrong.
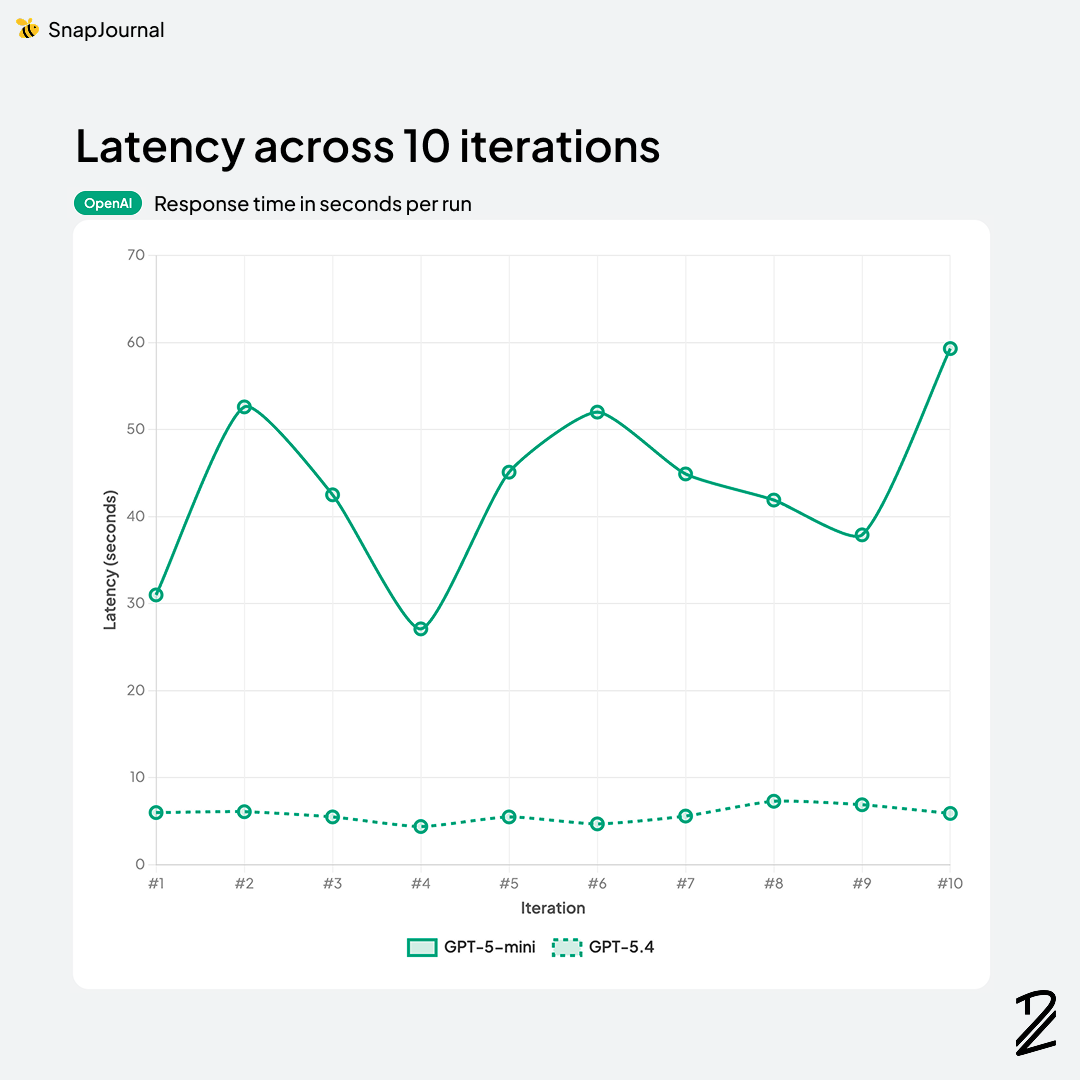
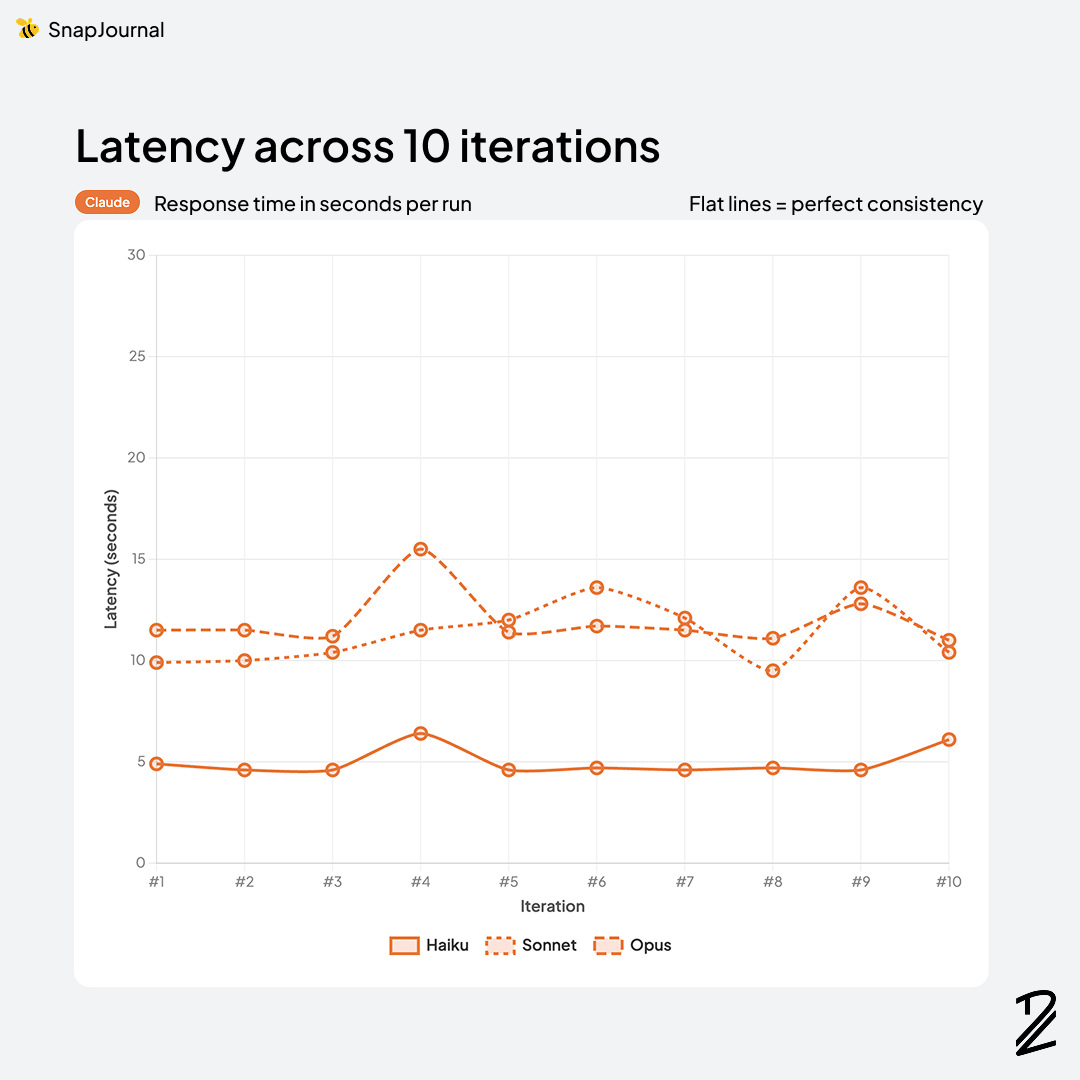
Claude Haiku-4-5 (5.0s) and GPT-5.4 (5.8s) were also quick, both under 6 seconds. Haiku is an interesting option if you need speed over peak accuracy.
Claude Sonnet-4-6 (11.3s) and Opus-4-6 (11.9s) — my top accuracy performers were in the middle of the pack. About 12 seconds isn't instant, but it's manageable with background processing.
Then things got wild. Gemini 3.1-pro took 26.3s, Gemini 3-flash took 31.4s (despite being called "flash"), and GPT-5-mini clocked in at 43.4s. The Grok reasoning models were even worse — 67.5s for Grok-4-1-reasoning and a painful 178 seconds for Grok-4. Three minutes for a 53.6% F1 score. That's the worst of both worlds.
For SnapJournal, I'm processing images asynchronously in the background, so a few extra seconds isn't a dealbreaker. I'd rather wait 12 seconds for Claude's 93% accuracy than get a 4-second response from Grok at 43%. The real takeaway? Speed and accuracy don't always correlate. Some of the fastest models were the least accurate, and some of the slowest were also inaccurate.
Consistency
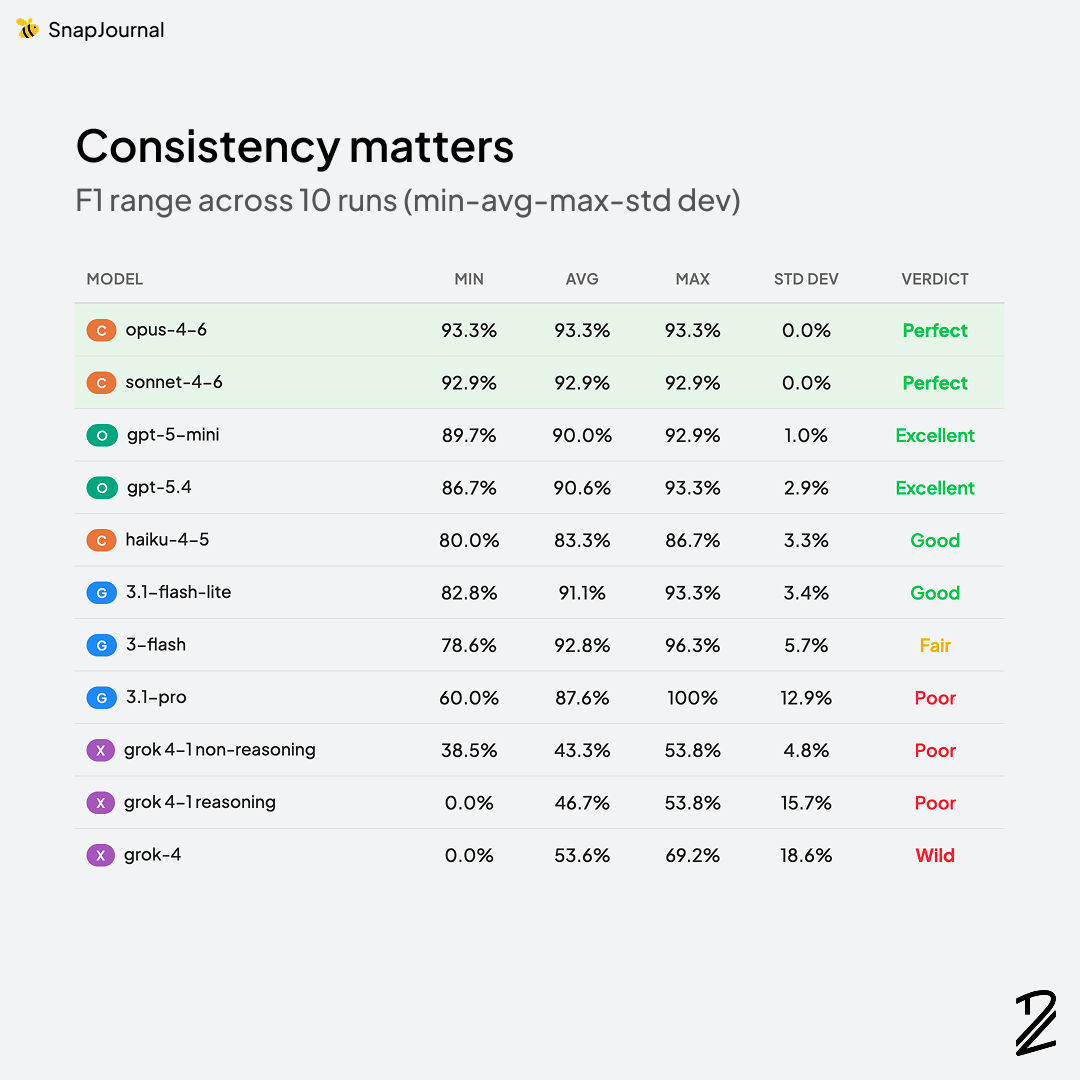
This one is a dealbreaker. If the same planner photo produces different results each time, users lose trust fast. Imagine confirming your schedule on Monday, then re-scanning on Tuesday and getting different events. That's a terrible experience. I ran the same image through each model multiple times to see how stable their outputs were.
Accuracy, speed, cost
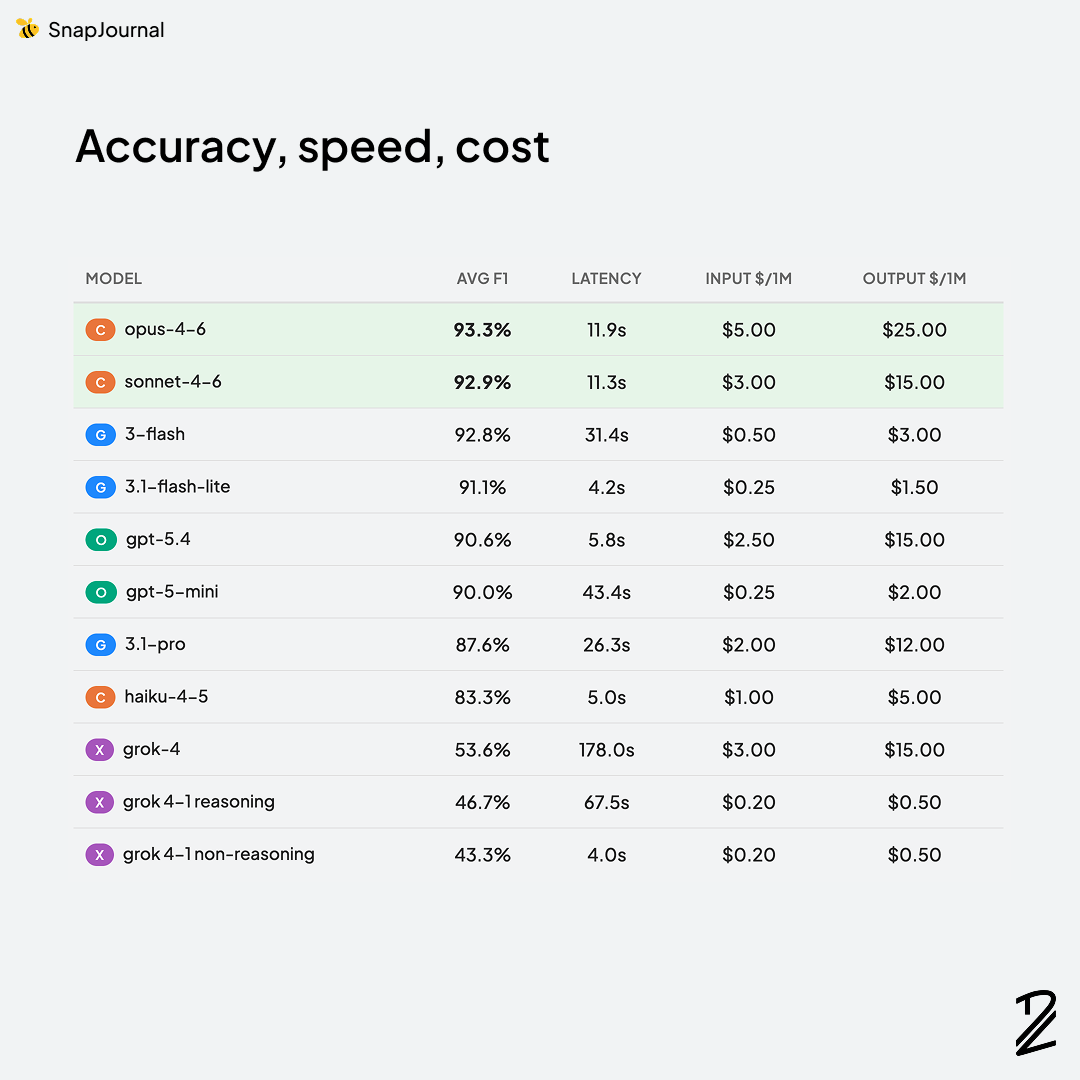
Here's where everything comes together. The best model needs to balance all three dimensions. There's no point in having the most accurate model if it costs 10x more per request or takes so long that users abandon the app.
Looking at the full picture, a few things stand out:
Claude Opus-4-6 has the highest accuracy (93.3%) but it's also the most expensive — $5.00/$25.00 per million tokens for input/output. That's a premium price tag that's hard to justify for an MVP.
Claude Sonnet-4-6 is right behind at 92.9% accuracy with a more reasonable $3.00/$15.00 pricing. But at 11.3s latency, it's not the fastest either.
Gemini 3.1-flash-lite is the hidden gem of this table — 91.1% accuracy, blazing fast at 4.2s, and absurdly cheap at $0.25/$1.50. That's 10-20x cheaper than the Claude models with only a ~2% accuracy drop.
Gemini 3-flash scores 92.8% (nearly matching Claude Sonnet) but its 31.4s latency is a problem — even with async processing, that's pushing it.
GPT-5.4 offers a decent middle ground at 90.6% accuracy, 5.8s latency, and $2.50/$15.00 pricing. Solid, but nothing that makes it stand out.
Grok models are either too slow, too inaccurate, or both. Grok-4 costs $3.00/$15.00 (same as Claude Sonnet) but scores 53.6% and takes 178 seconds. That's paying premium prices for the worst performance in the test.
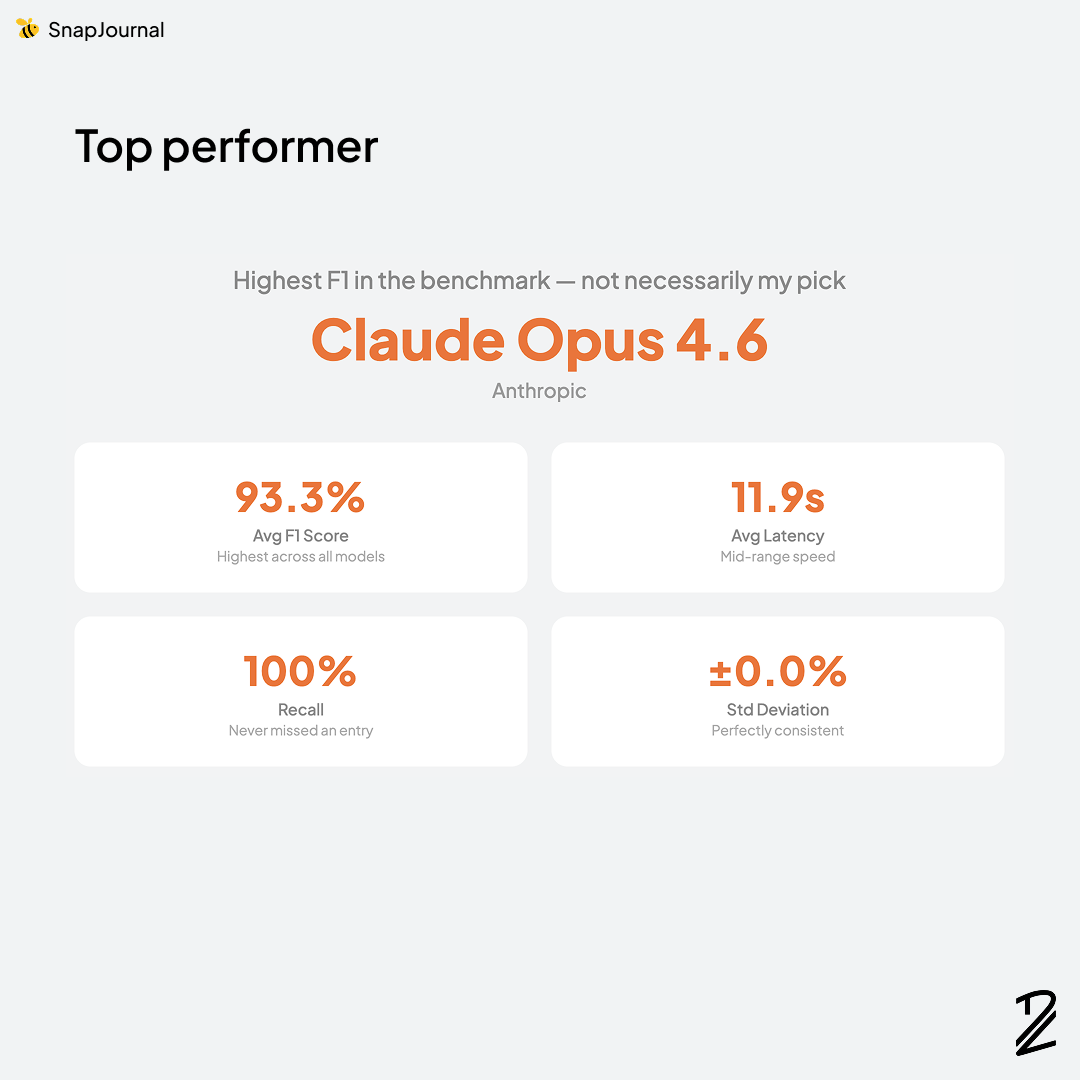
Top performer
Claude Opus 4.6 by Anthropic earned the top spot in my benchmark but having the highest F1 doesn't automatically make it my pick.
The numbers are hard to argue with: 93.3% average F1 score (highest across all models tested), 100% recall (it never missed a single entry), 11.9s average latency (mid-range speed), and ±0.0% standard deviation — perfectly consistent across all 10 runs.
That zero-variance stat is what really stands out. Every time I sent the same planner photo, I got the exact same results. No randomness, no surprises. For a product where users are trusting the AI to capture their schedule correctly, that kind of reliability matters more than raw speed.
Of course, top performer doesn't mean it's the right choice for every situation. Cost, latency, and scale all factor into the final decision. But purely on accuracy and consistency? Opus 4.6 was in a league of its own.
Key takeaways

Best overall: Claude Opus 4.6 — 93.3% F1 with 100% recall and zero variance across all 10 runs. It never missed a single event and gave perfectly consistent results every time. For a product where users need to trust the output, that consistency is everything.
Best value: Gemini Flash Lite — 91.1% F1 at just $0.25/1M input tokens and 4.2s latency. If budget is your primary constraint, this model delivers near top-tier accuracy at bottom-tier pricing. That's a remarkable cost-to-performance ratio.
Biggest surprise: Gemini Pro scored lower than Gemini Flash****. This one caught me off guard. Gemini 3.1-pro (87.6%) was wildly inconsistent — ranging from 60% to 100% F1 across runs. You'd expect the "pro" tier to outperform the lighter models, but for this specific task, the opposite was true. A good reminder that model naming doesn't always reflect real-world performance.
Grok's vision capabilities are still far behind. Both Grok models scored under 50% F1, and Grok-4 took 178 seconds per request. For handwriting recognition and structured data extraction, Grok simply isn't ready.
The biggest lesson from this whole process? Benchmarks are a starting point, not the answer. Your use case is unique. The model that tops a leaderboard might not be the best fit for what you're actually building. If you're integrating AI into your product, invest the time to run your own evaluation with your own data. It's one of the highest-ROI things you can do early on.
Bonus: The $7 request

After I finished my evaluation, I tried GPT-5.4 Pro. Once. Never again.
The numbers: 8 minutes 51 seconds of latency (531,066ms for a single request), roughly ~$7 per image extraction, and a 92.9% F1 score (P: 92.9% | R: 92.9%).
Here's the thing — the raw output was actually impressive. It returned 14 events for 14 expected, with 13 matching. It was smart enough to combine "AI Compare" + "run benchmark" into one entry, correctly merged "Handwrite letter" + "Go to USPS", and nailed tricky times like 14:30 and multi-hour blocks.
So yes, GPT-5.4 Pro might be the best reader in the room. But it comes at 150x the cost and 75x the latency of Claude Opus, which scored 93.3%. For a mobile app where users expect quick results, spending $7 and nearly 9 minutes per photo is a non-starter no matter how good the output looks.
Which one would you choose?
Every app has different needs. The model I picked works best for SnapJournal's specific requirements — handwriting recognition, spatial understanding, structured data extraction, and cost efficiency. But your project might have completely different priorities.
If you're building something that relies on AI vision, I'd encourage you to run your own tests rather than relying on leaderboard scores alone. The extra effort is worth it.
What would you have chosen?
